 GubboIT - Command
GubboIT - Command0 0
Words:
Get started
This app demonstrates speech command recognition using Deep Learning.
- Try words: Say one of the 18 words and see if the app understands you. If you have problems see How is the model performing?
- Control icon: Control how an icon moves using words.
How does it work?
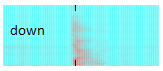
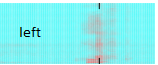
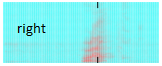
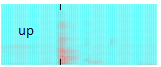
The microphone picks up your word and it is digitized by the sound card. The browser has real-time access to the sound data. This data can be seen as an image - a spectrogram (see above). The spectrogram can now be fed into a deep learning model for image recognition. So in principal word recognition is handled as image recognition.
One model with 18 classes (different words) is used by the app. The model (a convnet) is similar to the models used by the Digit app and is not described here. See Digit app for more info on models, training etc.
Input and output
The buttons can be activated in the ordinary way or by a voice command. A number on the button indicates what word/command to say. 1 means the word one, 2 means the word two. If you have problems with the word down you can use the word go.
- Try words/Stop button: Start or stop Try words.
- Control icon/Stop button: Start or stop Control icon.
- Words: What words/commands to say.
- Black area: Shows the predicted word and the probability of the word.
- Green counter: Number of outputs from the 'recognizer' software (number of callbacks).
- Red counter: Number of outputs from the 'recognizer' software that are discarded because the words are coming too fast.
- "Scroll" using voice: go or down scrolls down. stop scrolls to the top. Always end voice scrolling with stop to enable the buttons.
How is the model performing?
When I used Try words I had big problems with eight but also problems with nine and down. Is the problem my accent (Swenglish), my type of voice, or is threre something wrong with my app? I used the voice of Google Translate and the app was performing very well - so no general problem. My female partner (also Swenglish) tried the app with excellent result. So the problem seems to be that the model is not trained on my type of voice.
You may have noticed that sometimes words show up when you are not saying something. This is caused by background noice that the model is not trained on. The model is trained on some background noice but not on this noice. The most common word is up. To get up tap on your PC or phone or clap your hands once.
It is interesting that Control icon performs as well or better when you replace up, down, left, right with the "words" ah (up without p), dow (down without n), righ (right without t), lef (left without t).
Why Deep Learning?
Speech recognition is much older than Deep Learning. So why use Deep Learning? One reason is that the result is better than with older methods. Another reason is that using Deep Learning saves a lot of work. Hand-crafted feature engineering is not needed. The convnet does this work. It is an end-to-end model and special preparation steps are avoided.
Implementation
The app is written in JavaScript using TensorFlow.js for "Machine Learning" and Bootstrap for the UI. All code related to the app is run in the browser. The web server is only keeping the files of the app. The files (including the model) are downloaded to the browser. So the predictions are done in the browser.
The app uses the Speech Command Recognizer module and its pretrained model 18w. For more info see speech-commands at GitHub.
Copyright 2019 GubboIT
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
Acknowledgment
This app was inspired by the excellent book "Deep Learning with JavaScript" from Mannning Publications.
Home